Oh, new Boards of Canada album!
2026.05.29.
2026.05.26.
Bookmarked “Ferrari Luce – Ferrari.com”
I just love the design of this thing.
2026.05.25.
Making Bike into a thinking environment
-
I created a demo video of how I started using Bike 2.0 extensions.
-
They are pretty cool.
-
-
Essentially I want to set up a thinking space with reactive AI integration. Something like a simpler version of Obsidian, without any Electron crap.
-
I don’t plan to open-source these repos, because I don’t want to support them.
-
This is pretty customized to my workflow. I don’t think I can make them generic enough.
-
It is not that hard to build extensions with Claude Code. You can just take these ideas and build them yourself.
-
To get started, clone the example repos from the extension documentation, ask Claude to review them, and create a skill.
-
-
Here’s the demo video.
2026.05.11.
Back to blogging
-
I’m restarting the usage of this Bike outline based blogging thing.
-
I want to have an easy way to blog.
Honestly, the best thing about Spatialize Stereo on AirPods is that you can turn it off.
2026.02.02.
Bookmarked “Itsyhome – Control HomeKit from your menu bar”
Your entire smart home in the macOS menu bar. Cameras, lights, thermostats, locks, and more – just one click away.
2026.01.18.
Last two weeks from my Zettelkasten
I keep a Zettelkasten, a personal knowledge base where I write notes and connect them over time. I’m trying out writing about what’s happening there, we’ll see if it sticks.
It started with a video
I watched a video about M-shaped careers. People with too many interests (“scanners”) building deep expertise in multiple areas instead of forcing specialization. The Zettelkasten fits here as external memory that lets you switch topics without losing everything.
Three connected notes
My job is thinking, then AI executes. I don’t write code anymore, I review it while Claude writes and I direct. My work runs on two tracks: notes and feature plans for AI to implement, and infrastructure that makes AI execution reliable.
Clarify by prototyping, not planning. My old core value was “Measure twice, cut once”, which assumed execution was expensive. These days prototyping is cheaper than planning, so I just build stuff and figure it out as I go.
AI reframes depth from execution to directing. The M-shaped career model assumes depth means doing the work, but with AI handling execution, depth becomes about understanding enough to see patterns and direct the AI.
These three became permanent notes in my outline, and they’re all connected to each other.
PKM audit
As I use more AI tools these days, my old PKM setup started to feel off, so I ran an audit. The result was Each PKM tool should have one role. Tools work better when they do one thing, and my old setup had overlap everywhere.
Current pipeline:
- Capture: Drafts on mobile, Bike on desktop
- Process: Tinderbox or Claude Code
- Destination: Zettelkasten for knowledge, OmniFocus for action, DEVONthink for reference
- Output: Craft for project plans, iA Writer for polished posts
I also wrote about GTD having a gap. Refinement is a missing stage between Process and Organize. GTD assumes everything captured can be immediately classified as actionable, reference, or trash, but some ideas don’t fit any of these. They’re not procrastinated or blocked, they’re just unformed and still searching for shape. Someday/Maybe gets treated as a parking lot, but refinement is active, not passive. It needs systems for repeated contact with incomplete ideas until they’re ready to become either a Zettelkasten note or a project plan.
Most of these notes come back to the same thing: AI made execution cheap, so I’m rethinking how I work and how my tools support that. Three notes became permanent zettels, two are about my PKM setup, and one came from a video. That’s the last two weeks.
2026.01.17.
I can safely say that Liquid Glass is the Butterfly Keyboard of software design. The basic idea is great, but the execution sucks.
I just hope it won’t take years to fix it.
2026.01.13.
I had my two previous post in the wrong format, so outgoing links didn’t work. Fixed it.
Bookmarked “LinkEdit – Cocoa Productions”
Personal knowledge manager (PKM). Point to any folder and manage your Markdown and plain text notes. Create auto-updating links which can go in both directions.
Pretty early, but looks promising.
Bookmarked “sozercan/kaset: 📻 The missing YouTube Music macOS app”
A native macOS YouTube Music client built with Swift and SwiftUI.
Bookmarked “aaaaalexis/obsidian-cupertino: A native look and feel Obsidian theme designed for a clean, focused, and mobile-friendly writing experience.”
Cupertino is an Obsidian theme, optimized for desktop and mobile devices. Bringing clean, focused, comfortable reading and writing experience to your vault.
Looks pretty nice, but… it is still Electron under the hood.
2026.01.10.
Bookmarked “Updatest”
All your Mac updates. One beautiful interface.
Bookmarked “Owl”
Owl is a note-taking app currently under development for Apple platforms. An early version is available for Mac.
2025.12.28.
My Mind Is Not the CPU for Bureaucracy
I don’t usually do New Year’s resolutions, but this year I made an exception. It’s not a goal but a boundary, and it’s that I want to stop spending thinking capacity on problems AI can handle well enough.
Things like passport renewals, car maintenance, and health insurance paperwork aren’t intellectually hard problems for me. They’re high-friction re-entries into suspended projects that steal the same executive function I need for creative work. So I’m experimenting with an approach where Claude Code does the thinking and I become the hands and feet that execute.
You might be wondering why I’d give up that much control, but the thing is that I’m not giving up control over outcomes, just over the tedious context-reconstruction that precedes every action.
The Problem Isn’t Time, It’s Context
The standard productivity narrative says “do things faster.” But I’ve realized that for life admin, speed isn’t the bottleneck. The bottleneck is cognitive re-entry.
Every time I return to a bureaucratic project (health insurance setup, car inspection scheduling, government ID renewal), I pay a tax, and it’s not a time tax but a thinking tax. I have to reload the entire context: What did I do last time? Where’s that document? What’s the phone number? What did the person say?
This context reconstruction drains the exact same mental resource I need for interesting problems like creative work and engineering challenges, the stuff that actually benefits from my personal attention.
The insight is simple, which is that most life admin problems are not hard. They’re just high-friction re-entries. The thinking required isn’t creative; it’s reconstructive. And in my experience, Claude Code handles reconstructive thinking reasonably well (though I still verify critical details).
Flipping the Collaboration
For knowledge work, everyone talks about AI as a copilot where the human captain does the thinking and the AI assistant helps with execution.
For life admin, I flipped this around so that Claude does the thinking while I handle the execution.
In my early experiments, this architecture shows promise:
- Claude does the thinking (loads context, synthesizes history, generates call scripts, decides what to say)
- Human does the grunt work (physically holds the phone, drives to the government office, signs the document)
It might sound like I’m demoting myself to grunt work, but for me the hard part of life admin was never the physical execution. It was always the mental overhead of figuring out where I left off and what to do next. Once I know what to say and have my documents ready, making the call is easy (though I still need to think on my feet when conversations go sideways).
Ghost in the Shell
Now let’s talk about how this actually works. For Claude to be useful, it needs context. It can’t just be a chatbot I explain things to each time. It needs to temporarily inhabit the project’s accumulated knowledge.
I call this approach “Ghost in the Shell” (borrowing from the anime, where consciousness can inhabit different bodies). In my version, the “shell” is the project’s accumulated data and the “ghost” is Claude’s reasoning capability that temporarily inhabits it.
Each project has a brain: notes, meeting transcripts, task history, linked documents. When I trigger a task, Claude loads this brain and reasons from that context.
I should mention the technical setup, which is that I use Claude with MCP integrations that can read from my document database and task manager. I use Mac-specific tools (DEVONthink for documents, OmniFocus for tasks, Hookmark for cross-app links), but the principle should be tool-agnostic since any setup that can aggregate project context and feed it to an LLM would work.
When I select a task in OmniFocus, Claude follows the project hierarchy upward to find the parent project, then loads all linked documents and notes. It builds a timeline of what happened. Then it can act with full context, not just respond to isolated prompts. Sure, Claude doesn’t truly “understand” the project, but it synthesizes the available information well enough for bureaucratic tasks.
The One Question Rule
You might ask whether managing AI becomes its own overhead, and yes, it can. I’ve found that AI assistants can become another attention sink through clarifications, follow-ups, and re-prompts, and before you know it, managing the AI becomes a new kind of bureaucracy.
So I built in what I call the “one question rule.” If Claude is missing information, it can ask one question maximum. Then it has to provide a best-effort plan with assumptions stated. If it’s still stuck, it downgrades by first moving from doing the task to proposing a plan, and then to explaining how this type of problem generally works so I can handle it myself.
This prevents Claude from becoming needy. It forces decisive action with explicit assumptions rather than endless clarification loops.
I also added risk-based escalation. “Autopilot” here means Claude proceeds without asking for confirmation:
- High risk (finance, medical, identity): never autopilot
- Medium risk: autopilot only for prep work (drafts, research)
- Low risk: full autopilot allowed
This doesn’t prevent all errors. I still need to review what Claude produces, and I’ve caught it confidently stating wrong details. But the guardrails prevent the worst-case scenarios while keeping friction low for routine tasks.
Closing the Loop
Claude doesn’t just prep and disappear but waits for me to come back with results.
Here’s a typical flow:
Claude: "Here's your call script for the mechanic. Key points to cover:
timing, parts availability, price estimate. Come back when done."
[I make the call]
Me: "Done. He said Tuesday at 10am works, and the part needs to be ordered."
Claude: Creates follow-up task that surfaces on the appointment date,
logs the outcome to project notes (so next time I have this
context), links everything together.This conversational loop keeps Claude as the orchestrator throughout. Every interaction gets logged back to the project’s brain, so next time the context is even richer.
What I Actually Delegate
The action types fall into three modes based on how much autonomy Claude gets:
Autopilot (Claude does the work, I review results): Research tasks where Claude queries Perplexity or analyzes code. Processing tasks where it extracts key points from articles or documents. Documentation tasks where it saves findings to DEVONthink and creates links between related items.
Propose (Claude preps, I decide and act): Phone calls where Claude loads my last conversation with someone, generates a script, and tells me what questions to ask. Emails where it drafts messages based on project context. Setup tasks where it researches best practices and generates step-by-step guides. Decisions where it builds comparison matrices and recommends options.
Teach (Claude explains, I learn): Learning tasks where Claude curates resources, creates a study plan, and suggests hands-on exercises, but I do the actual learning.
The key insight is that even when Claude can’t do the task, it can reduce my cognitive load significantly. For a phone call, I usually don’t have to remember anything because Claude already looked up my last interaction with that person and what we discussed. I just read the script (though I still need to adapt when the conversation goes sideways).
Action Types
I built a library of action types as markdown files that Claude reads when working on a task. Each type (research, review, process, draft, analyze, document, setup, learn, coordinate, execute, spec) defines a prep pattern for what Claude should do before I act, a capture pattern for logging results afterward, and which tools to use. For example, the “draft” type handles phone calls and emails by loading contact details and past conversations, then generating a script or message draft.
The process of building this library is ongoing. I pay attention to what types of actions I do repeatedly, then figure out how Claude could help with each one. Some actions start in Propose mode and graduate to Autopilot once I trust the pattern. The goal is to keep expanding what can be delegated as I discover new friction points.
Claude generates plans fresh each time using these patterns plus the project’s accumulated context. In theory, this gets smarter with each use because the context compounds. I haven’t measured this rigorously, but I’ve noticed Claude’s prep work improving as project histories grow richer.
The Real Risk of AI Assistants
What I’ve found is that the real risk of AI assistants isn’t that they make you lazy but that they make you a manager of an intern that asks infinite questions.
I prevent that by design through a kind of contract with Claude that includes clear modes of operation, risk-based guardrails, explicit definitions of done, and a hard cap on questions, so it behaves like a capable assistant rather than a needy one.
Is this worth the setup time? I spent a day building the infrastructure. Whether it pays off depends on how many bureaucratic projects I run through it. Ask me in six months.
For now, I’m experimenting with reserving my thinking capacity for interesting problems. Everything else gets delegated to the ghost in the shell.
2025.12.26.
Bookmarked “Writing Workflow”
This is actually a pretty interesting way to think about which app should be used for which type of writing.
Question: What am I writing?
a. Longform – a novel or non fiction piece of more than 2,000 words.
Answer: Scrivener
b. Shortform – a blog post or e-mail or report or some such. Something that I’m “drafting”.
Answer: IA Writer
c. Notes – an idea, a thought, a snippet or reminder. Something that may grow, or may link, but does not in its current form represent a draft towards publishing.
Answer: Obsidian
Question: where do I “archive” writing?
Answer: DevonThink
DevonThink is searchable, organised and backed-up. Perhaps archiving is an annual process – so at the beginning of 2022, I archive any and all pieces in IA Writer that predate 2021, leaving a minimum of 1 year and a maximum of 2 years in situ. Scrivener projects can be archived too. (In Plain Text)
See more about this topic:
Blogging from Bike today
-
I’m writing on my blog from Bike today, which I still love.
-
Also related but in a different way
-
Thinking in Threads with Bike Outliner
-
Note: sometimes I wonder why do I keep a separate Zettelkasten around, since WordPress and my blog could solve that problem easily.
-
-
-
Writing in an outliner and publishing directly kinda works for me, since I’m not editing posts in some weird CMS (even if MarsEdit is awesome).
-
I like how easy it is to move rows around.
-
It’s freeform text, but on the other hand, it’s still pretty structured.
-
-
I should write more posts from here. It would make sense for quick posts like this, no hard editing, even spelling errors.
-
Nobody cares, the main idea is to push content which can be interesting.
-
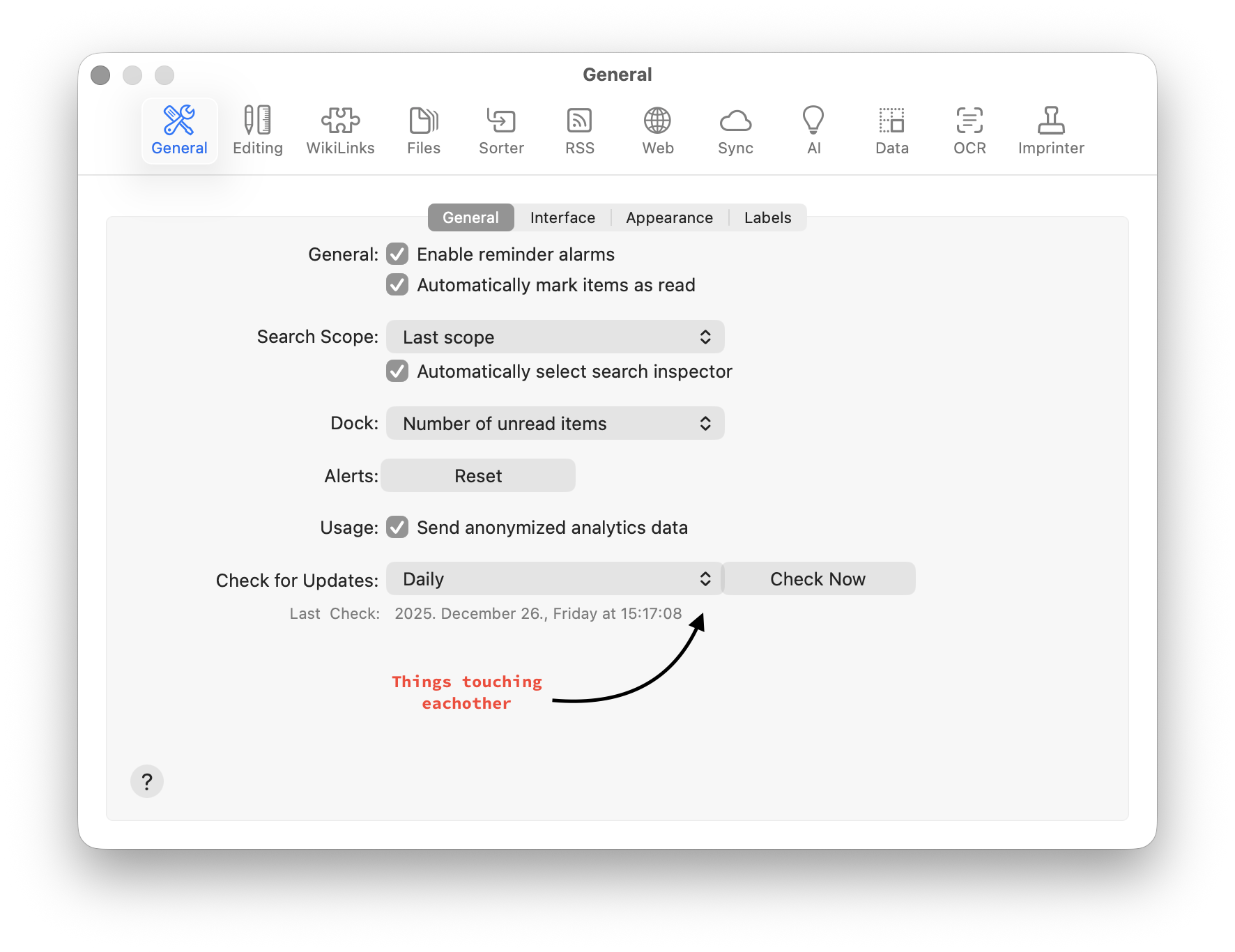
DEVONthink and Liquid Glass testing
-
There is a new beta of DEVONthink in Liquid Glass.
-
Looks pretty nice.
-
-
There’s a new app icon, which is similar to DEVONthink To Go 4.
-
Some smaller UI issues
-
The magnification glass on the right has a small UI issue.
-
General settings drop-downs are touching each other.
-
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2025.12.21.
Brainstorming about macOS note-taking apps
-
The Archive (native)
-
Plain-text Zettelkasten app with wiki-links, fast search, and minimal UI. File-based (markdown), local-first. The primary tool for this zettelkasten. (Workflow context)
-
My current or previous usage of the app.
-
Primary zettelkasten tool – all permanent notes live here. Main journaling and thought capture. Search and browse the knowledge network. Private notes hidden from published site. (Content pipeline)
-
Part of three-tool thinking system: Zettelkasten (The Archive) for journaling and permanent notes, TaskPaper for planning/brainstorming, Emacs for code experiments. (Different thinking modes)
-
-
-
Articles and websites
-
-
Summary of this article.
-
Manan Khattar’s case for The Archive: 1,330 notes (350K words) in plain text. Speed and keyboard-centric design minimize cognitive friction. Search-driven workflow enables queries like
#literature #inbox (productivity OR writing) (202407 OR 202408). Native Zettelkasten support from zettelkasten.de’s creator. -
Trade-offs acknowledged: unique identifier requirement makes wikilinks less readable than Obsidian. No plugin system—requires Alfred workflows for full functionality. No mobile app (uses 1Writer as workaround).
-
Core thesis: tool choice matters less than sustaining writing-focused thinking habit. The Archive’s speed accelerated his adoption.
-
I got to know kindaVim from this article.
-
Actually, I already wrote about this before: Bookmarked “kindaVim”
-
There are videos about kindaVim: kindaVim – YouTube
-
Most of them just ramblings.
-
-
This is another app from the same guy for keyboard based UI navigation: Wooshy
-
-
-
-
-
iA Writer (native)
-
Distraction-free markdown editor with focus mode, syntax highlighting, and publishing integrations. Typography-first design from Information Architects.
-
My current or previous usage of the app.
-
Drafting and linking workflow via smart folders. #Drafting folder shows notes being written, #Linking folder shows notes ready for outline placement. The final drafting step before zettelkasten integration. (Content pipeline)
-
-
-
Articles and websites
-
Writing Workflow – Stuart Lennon
-
Summary of the article, focusing on the question “What am I writing?” section.
-
Stuart Lennon’s framework: three writing categories.
-
Longform (2000+ words) in Scrivener for novels/non-fiction.
-
Shortform drafts in iA Writer for blog posts and reports.
-
Notes ideas in Obsidian for thoughts not yet publication-ready.
-
The “What am I writing?” question determines tool selection. Plain text everywhere for portability. DEVONthink as archive. Open question: whether Drafts could serve as unified entry point with automated routing.
-
-
-
-
Bike (native)
-
Native macOS outliner with fast keyboard navigation, collapsible hierarchy, and scripting support. Version 2 adds extensions API and custom attributes. The app running this outline.
-
My current or previous usage of the app.
-
Core organizing tool for the content pipeline. Ideas get arranged in Bike outlines before export to zettelkasten via Drafts. Also manages the folgezettel outline structure. (Content pipeline)
-
Decoding files are raw Bike outlines for blog posts. All content ready for publishing; private things go to interstitial journal instead. (Journal-type apps)
-
Now used as AI-integrated thinking space with thread-watch and MCP server. Reactive prompting via @question attributes. (Bike thinking tool exploration)
-
-
-
Articles and websites
-
-
TaskPaper (native)
-
Plain-text task management using indentation and tags. Same developer as Bike. Good for project brainstorming and task breakdown. (Workflow context)
-
My current or previous usage of the app.
-
TaskPaper role: plain-text planning and brainstorming for project-specific thinking and task breakdown. OmniFocus shortcut triggers “project brainstorming” in TaskPaper. (Different tools for different thinking modes)
-
Historical use: interstitial journaling. Deprecated that role, moved journaling back to zettelkasten. Brainstorm sessions now live in the journal rather than separate files. (Plans for TaskPaper changes)
-
Workflow: Bike for initial outlining, switch to TaskPaper once plan solidifies. Part of the plain-text system alongside The Archive and Bike. (Text-based system)
-
-
-
Articles and websites
-
-
Drafts (native)
-
Quick capture app with powerful actions system for routing text to other apps. Automation-first design. Inbox for thoughts, not storage.
-
My current or previous usage of the app.
-
Export gateway from Bike to zettelkasten. Ideas organized in Bike get exported through Drafts into new notes. Also used for quick capture on Apple Watch at night. (Content pipeline)
-
MCP server spec exists for automation integration. AppleScript-based CRUD operations planned but automation permissions need resolution first. (Drafts MCP spec)
-
-
-
Articles and websites
-
-
Craft (native)
-
Block-based document editor with rich formatting, folder structure, and cross-device sync. Apple Design Award winner, positioned between Notion and traditional notes.
-
My current or previous usage of the app.
-
Primary reading queue manager via Readwise-Craft syncer integration. Articles flow in, get processed with highlights, then export to zettelkasten. MCP server enables AI automation. (Readwise-Craft syncer)
-
Daily notes workflow for session logging and project tracking. Block-based structure good for moving content between documents. (Content pipeline)
-
-
-
Articles and websites
-
-
DEVONthink (native)
-
Document/knowledge management database with AI classification, OCR, and smart groups. Stores anything, indexes everything. Research-grade organization.
-
My current or previous usage of the app.
-
DEVONthink role: document archive and reference storage. Articles, PDFs, web archives, receipts. AI classification and OCR. Research-grade organization with smart groups. (Incremental reading system)
-
Reading queue integration: documents captured to DEVONthink appear in OmniFocus @Read/Review perspective. The queue is in OmniFocus, content stays in DEVONthink.
-
MCP access via mcporter enables AI agents to search and retrieve DEVONthink content. Source references in older zettelkasten notes use x-devonthink-item:// links.
-
-
-
Articles and websites
-
-
Obsidian (Electron)
-
Plugin-extensible markdown vault with graph view, backlinks, and community ecosystem. Electron-based, local files. Power-user PKM tool.
-
My current or previous usage of the app.
-
Limited use currently. Explored for AI integration with Cursor but zettelkasten workflow remains in The Archive. Considered for consolidating Planning folder but not active. (Obsidian exploration)
-
-
-
Articles and websites
-
-
OmniOutliner (native)
-
Professional outliner from OmniGroup with styling, columns, and export options. More structured than Bike, less nimble. AppleScript support.
-
Articles and websites
-
-
MindNode (native)
-
Visual mind mapping with clean design and focus mode. Exports to various formats. Good for brainstorming spatial relationships, less for linear text.
-
My current or previous usage of the app.
-
Used for preparing content before processing. Ideas get connected to mindmaps with tags and links before moving to notes. Public mindmaps shared online (e.g., Japanese Design and Aesthetics). (Processing workflow)
-
-
-
Articles and websites
-
-
Scapple (native)
-
Freeform note board from Literature and Latte (Scrivener makers). Spatial arrangement of text snippets with connection lines. Idea exploration before structure.
-
Articles and websites
-
-
NotePlan (native)
-
Markdown notes with calendar integration and task management. Daily notes workflow with backlinks. Hybrid of journaling and task app.
-
Articles and websites
-
-
Distill (Tauri)
-
AI-native thinking tool with append-only threads and contextual awareness. Local-first with cloud sync. Discussed earlier in this document.
-
My current or previous usage of the app.
-
Explored briefly – app installed, bug filed about quick capture window positioning with right-side Dock. Append-only threading concept influenced thread-watch development. (Reactive prompting)
-
Removed from active toolchain – no current use case. Keep app installed for existing content. (Journal-type apps conclusion)
-
Explored briefly – app installed, bug filed about quick capture window positioning with right-side Dock. Append-only threading concept influenced thread-watch development. (Reactive prompting)
-
Removed from active toolchain – no current use case. Keep app installed for existing content. (Journal-type apps conclusion)
-
-
-
Articles and websites
-
-
Bear (native)
-
Markdown notes with tags, nested tags, and backlinks. Clean native UI. Simpler than Obsidian, more polished than most.
-
Articles and websites
-
-
Ulysses (native)
-
Long-form writing app with library management and publishing targets. Markdown-based but hides syntax. For writers shipping manuscripts.
-
Articles and websites
-
-
Noteship (native)
-
Minimal sticky-note style capture app. Menu bar access, quick entry. Capture-focused, not organization-focused.
-
Articles and websites
-
-
Notebooks 3 (native)
-
Hierarchical notebook app with nested books and markdown support. Cross-platform sync. Traditional notebook metaphor with modern features.
-
Articles and websites
-
-
Scrivener (native)
-
Long-form writing IDE with binder, corkboard, and compile system. For novels, screenplays, research papers. Structure-first drafting.
-
Articles and websites
-
-
Tinderbox (native)
-
Hyper-customizable note database with agents, attributes, and visual maps. Steep learning curve, extreme power. For complex knowledge work and research.
-
My current or previous usage of the app.
-
Higher-level life management – dreams, someday/maybe ideas, things above projects. Scripts connect OmniFocus to Tinderbox for two-way sync. Ideas and goals live here; projects get managed in OmniFocus. (Tinderbox for life management)
-
Incremental Reading document watches Readwise chunks folder. Considered skipping from general chunk processing due to workflow friction getting content in. (Tinderbox workflow friction)
-
-
-
Articles and websites
-
-
BBEdit (native)
-
Professional text editor with grep, syntax coloring, and scripting. Not a note app per se – a text tool that handles notes. 30+ years of macOS development.
-
Articles and websites
-
-
Org-mode with Emacs (native)
-
Plain-text outliner inside Emacs with TODO states, scheduling, and literate programming. Keyboard-driven, infinitely extensible. Used for programming experiments. (Workflow context)
-
My current or previous usage of the app.
-
Current Emacs usage: Org Mode for programming experiments and literate programming. Still exploratory – set up OmniFocus shortcut for “programming docs” but workflow not fully established. (Different Tools for Different Thinking Modes)
-
Org Agenda navigation shortcuts documented separately – day/week views, date jumping, standard Emacs keybindings. (Org Agenda Shortcuts)
-
Position in tool ecosystem: Zettelkasten (The Archive) for journaling and permanent notes, TaskPaper for planning/brainstorming, Emacs for code experiments. Three tools, three thinking modes.
-
-
-
Articles and websites
-
-
Strflow (native)
-
Stream-of-consciousness capture app with AI integration. Continuous text flow rather than discrete notes. Early-stage product.
-
My current or previous usage of the app.
-
Short idea dumps when thinking about something – ideas then move to OmniFocus/Bike. Removed from active toolchain; no current use case. App kept installed for existing content. (Journal-type apps conclusion)
-
Short idea dumps when thinking about something – ideas then move to OmniFocus/Bike. Removed from active toolchain; no current use case. App kept installed for existing content. (Journal-type apps conclusion)
-
-
-
Articles and websites
-
-
NotePlus (native)
-
Native macOS LLM client (~10MB). Supports OpenAI, Gemini, Anthropic, Ollama, DeepSeek, Copilot. Different category than Bike—this is a chat interface with note-taking features, not an outliner. The “True Native” claim positions it against Electron apps.
-
Thinking in Threads with Bike Outliner
I’ve been looking for a tool that supports threaded thinking. Distill nails the concept: you think out loud into threads, and AI agents respond inline without breaking the flow. But it’s pricey, hosted, and not native. I want local files so I can use git.
So I built something similar with Bike.
The Threading Idea
The core concept is append-only threading. New thoughts go at the end. No reorganizing, no inserting between existing ideas. The thread keeps expanding.
This preserves how ideas actually develop. When I capture thoughts in a traditional outline, I’m constantly deciding where things go. That decision-making interrupts the thinking. With append-only, there’s no decision. New thought? Add it at the end. Want to go deeper? Indent.
I’ve written about this before in Reviewing append-only workflows. The pattern keeps showing up: Mastodon threads, chat-based note apps like Gibberish, and now Bike.
Why Bike
Bike is a macOS outliner (think Workflowy, but native and scriptable). What makes it work for threading:
- Indentation for depth – Drilling into an idea by adding child rows
- Sequencing – New rows extend the thread chronologically
- Grouping – When patterns emerge, I can nest siblings under a new parent
The structure emerges from the content. I start typing, indent when going deeper, and the hierarchy forms naturally.
Adding AI Inline
Distill’s insight is that AI agents can watch threads and respond without being addressed directly. I wanted that for Bike.
So I built thread-watch. It watches my outlines for rows tagged with @question and adds responses as indented blockquotes. The workflow:
- Think out loud in the outline
- Tag uncertainties with
@question - Run thread-watch (keyboard shortcut)
- Responses appear as children of the question
- Keep thinking, keep appending
The responses stay in the thread. They’re part of the thinking record, not a separate conversation.
Here’s what it looks like in practice:
Reactive Prompting
The technique I use for AI responses is what I call reactive prompting. The agent isn’t addressed directly. It responds to the thought stream.
The system prompt tells Claude to write like margin notes in a book: factual, terse, no “I found that…” discovery narrative. This matters because conversational AI responses feel like interruptions. Reactive responses integrate with the thinking instead.
Connecting to the Zettelkasten
The agent has access to my Zettelkasten folder. Before answering, it searches for relevant existing knowledge and links back. I was outlining something about capture workflows, tagged it @question, and the agent found a note I’d written two years ago. The response linked back, and I restructured my outline based on what past-me had already figured out.
Bike becomes the staging area for fast thinking. When something crystallizes, I copy it to the zettelkasten as a permanent note.
The Trade-Off
Append-only limits restructuring. If the structure is wrong, I can add cross-references and synthesis rows, but I can’t reorganize without losing the thinking record.
Tagging @question and running the tool is still an interruption. It’s smaller than switching to a chat window, but not invisible.
Why This Works
Standard outlining is about organization. Threading is about capture. I’m not building a perfect structure. I’m externalizing thinking fast enough that I don’t lose it, and the AI assists inline when I need context.
The structure emerges. The thread keeps expanding.
2025.08.30.
First Impressions of Liquid Glass in macOS Tahoe
I’ve been running macOS Tahoe‘s new Liquid Glass design on my MacBook Air for a couple of days. Parts work, parts don’t, but most people will adapt quickly enough.
The smart thing Apple did was leave 3rd-party apps alone. They run with the previous design intact, giving you familiar anchors while you adapt to the new interface. Electron apps will probably never update, which might be a blessing.
The dynamic background adaptation is broken. Buttons shift from black to white as the background changes, and it’s jarring every single time. Toolbar consistency is all over the place too. Photos and Mail use progressive blur with gradients while Safari keeps the old blurred rectangle, with no apparent logic to which apps get which treatment. Scrolling through Photos is particularly painful as the interface flips from black to white and back again as you move through your library. This isn’t a minor polish issue. It’s a fundamental problem with how the adaptive system responds to content, and Apple should fix it.
When the general public gets their hands on Liquid Glass, I’m sure people will complaint. The current state is too buggy to survive contact with millions of users. I expect iterative improvements throughout the OS 26 cycle as the design gets tweaked based on user feedback.
The foundation has potential, but the background adaptation logic needs fixing. Until then, it’s a work in progress.
2025.08.26.
Solving Token Waste with Claude Code Personas
The new /context command in Claude Code revealed how I’m wasting tokens by having all MCP (Model Context Protocol) tools loaded into one session for every conversation. When I’m in the middle of development, I don’t need OmniFocus task management or DEVONthink database tools.
Based on subagents I had the following idea: what if I split Claude into specialized personas, each loading only the tools it actually needs?
Creating Focused Personas
Instead of one bloated agent trying to do everything, I created three specialized personas:
Main Persona (cc): The clean, focused default. Just filesystem, bash, and macOS automation via one MCP server. This handles most of my daily coding tasks with minimal tool overhead.
Research Persona (ccr): The deep investigation specialist. Loads Zen for multi-model reasoning (GPT-5, O3, Gemini Pro), Context7 for library docs, Octocode for code search and analysis, and Codex for deep code research. When I need to debug something complex or review architecture, this persona has the tools.
GTD Persona (ccg): The productivity workflow expert. Connects to OmniFocus for tasks, Obsidian for notes, DEVONthink for documents, and HyperContext for calendar management. This persona focuses on productivity workflows and task management.
Each persona also has access to subagents for specialized tasks, adding another layer of capability without wasting more tokens.
The implementation lives in my dotfiles as simple shell functions:
# Main persona - clean and fast
cc() {
claude ${*} --dangerously-skip-permissions
}
# Research persona with specialized tools
ccr() {
claude ${*} --dangerously-skip-permissions \
--model opus \
--mcp-config ~/.claude/mcp-research.json \
--append-system-prompt "You are a code research and analysis specialist \
focused on deep technical investigation, multi-model reasoning, and \
comprehensive code review. Your expertise includes security auditing, \
architecture analysis, debugging complex issues, and researching best \
practices across codebases. You leverage multiple AI models for consensus \
building, use Context7 to fetch up-to-date library documentation, analyze \
GitHub repositories for patterns with Octocode, and generate thorough \
technical documentation."
}
# GTD persona with productivity tools
ccg() {
claude ${*} --dangerously-skip-permissions \
--model opus \
--mcp-config ~/.claude/mcp-gtd.json \
--append-system-prompt "You are a GTD specialist orchestrating a \
multi-layered knowledge system where OmniFocus drives project execution, \
Obsidian captures notes and knowledge, and DEVONthink archives reference \
materials. You excel at processing inboxes across all three systems, \
organizing projects with proper next actions, capturing meeting notes \
with task extraction, and maintaining a trusted system for all personal \
and professional information. Your expertise includes creating bidirectional \
links between systems using Hook and maintaining clear separation between \
active project work and archived reference materials."
}
Each persona loads its own MCP configuration file, containing only the relevant tool servers. The --append-system-prompt flag gives each persona a specialized identity and deep expertise in their domain.
The Delegation Pattern
The most powerful aspect isn’t just the separation. It’s the ability for personas to delegate to each other. This creates a network of specialized expertise without loading unnecessary tools.
When delegation happens, I must approve it first. The main persona will say something like: “I’d like to ask the research persona to analyze this Rails controller for N+1 queries using its specialized tools.” Once I type “approved” or “go”, the delegation proceeds.
The delegation always runs in the background using the Bash tool:
// How the main persona actually delegates
Bash({
command: 'ccr -p "Analyze this Rails controller for N+1 queries and performance issues"',
description: "Ask research persona to analyze Rails performance",
run_in_background: true
})
This pattern works both ways. I can also delegate GTD tasks with a simple OmniFocus link:
# Ask GTD persona for comprehensive project review ccg -p "/gtd:project-review omnifocus:///task/jP9S4CFgPin"
The GTD persona doesn’t just fetch tasks. It discovers linked resources through Hookmark, pulls references and meeting notes from DEVONthink, reads project plans from Obsidian, builds a complete timeline, and suggests concrete next actions based on the full project context. All while the main persona continues with development work.
The background execution is key. The delegating persona doesn’t block waiting for results. It can continue working on other aspects while the specialized persona handles its domain-specific task.
What Changed
The token savings are significant, but the real benefit is focus. Each persona does one thing well with the right tools for that job. The system prompts shaped distinct behaviors. The main persona stays lean and fast. The research persona leverages multiple AI models for deep analysis. The GTD persona navigates my entire productivity stack.
2025.08.17.
Bookmarked “Making Software”
A reference manual for people who design and build software.
Pezeta Progress Log
Spent today designing the Rails controller layer for Pezeta.
I analyzed Capito, an envelope budgeting prototype I built seven years ago. Standard approach – categories as envelopes, track balances, show what’s left to spend, like YNAB. But Pezeta takes a different angle. Instead of manually managing category balances, I’m building a goal-oriented system where users define financial objectives and the system calculates the monthly allocations needed to achieve them.
For the controller architecture I designed five main tasks:
Authentication & Ledger Foundation – Auto-create ledgers with system categories when users sign in the first time. System categories like Income and Safe to Spend get created automatically, so no manual setup required.
Budget Controller – Returns a single JSON endpoint for now, focused on Safe to Spend calculation and future goal balances. This is what the UI will display prominently, not a list of category balances.
Categories Controller – Standard CRUD for user-defined categories. Goals are implemented as special categories with allocation rules that determine how they get funded each month.
Monthly Allocations – This is where goal-driven allocations get applied, but users can override them when needed.
Test Infrastructure – Rails conventions with fixtures that include the system categories.
I’m sticking with pure Rails MVC patterns, so no service objects, no complex abstractions. Business logic lives in models, controllers stay thin, everything renders JSON for now since we don’t have a Turbo-based UI yet.
This foundation should make the goal system feel automatic rather than manual.
2025.07.15.
Pezeta Progress Log: Day 9
I built the model layer for goal-oriented budgeting in Pezeta today. This is the implementation of the goal system I’ve been designing over the past week.
I’ve laid the foundation for four distinct goal types:
- Someday Goals – For big purchases. Save until you hit your target amount, then stop allocating.
- Monthly Goals – For recurring commitments. Allocate a fixed amount every month, like subscriptions or regular savings habits.
- Deadline Goals – For time-bound expenses. Spread the target amount evenly across the remaining months until your due date.
- Reserve Goals – For emergency funds. Maintain a buffer of N months of average expenses based on your actual spending patterns.
I still need to test all of this thoroughly, but the models are in place and the calculations are working. What I like about this approach is how it will turn vague financial intentions into concrete monthly actions. Want to save $5,000 for a vacation by next December? The system can calculate exactly how much to set aside each month. Need three months of expenses in your emergency fund? It’ll figure out what that means based on your actual spending patterns. The system tracks progress over time, adjusts recommendations based on current balances, and integrates smoothly with the existing budget structure.
Next up is building the UI layer. The foundation is solid, but there’s still work to do before I can actually use these goal features in my own budgeting workflow.
2025.07.13.
On Deleting Second Brains
Two nights ago, I deleted everything.
Every note in Obsidian. Every half-baked atomic thought, every Zettelkasten slip, every carefully linked concept map. I deleted every Apple Note I’d synced since 2015. Every quote I’d ever highlighted. Every to-do list from every productivity system I’d ever borrowed, broken, or bastardized. Gone. Erased in seconds.
What followed: Relief.
Sometimes it’s good to delete things, but a second brain isn’t an end goal. The sole purpose of a second brain is to help achieve some form of output. It serves as a tool to organize thinking for the future.
The problem with output is that we often don’t know what it will look like when we start. What a Zettelkasten (and GTD too) acknowledges is that you’ll have an outcome of some kind and you need a framework to manage it. That’s all.
People who capture their ideas then leave them there are still doing the same thing, but can probably think through their output in their head. I do that sometimes too, and it’s fast.
But as soon as I’m working on anything that requires more thinking capacity than I currently have, I reach for PKMs and task managers to handle it.
I usually split my long-term project-specific Zettelkastens off from my main one, though.
Previously:
- Every idea we execute should have some form of artifact at the end: a blog post, a Zettelkasten note, a presentation, an email, etc.
- Using Mastodon’s threads for thinking out loud
- Using iA Writer as an end-to-end writing system
- Reviewing append-only workflows
- Append-only storage and developing ideas
2025.07.12.
Bookmarked “LisaGUI”
LisaGUI is a web OS inspired by the Lisa Office System, Apple’s first graphical user interface (GUI). It aims to perfectly recreate the Lisa’s iconic 1-bit UI directly in your browser.
Lisa had so many great UI ideas. We still have the concept of stationary pads on macOS today.
2025.07.11.
Pezeta Progress Log: Day 5
Today I worked on planning Pezeta’s goal system. I experimented with using two AI agents to collaborate on breaking down the work: Claude Opus 4 as the coordinating agent with read/write access, and ChatGPT o3 through Repo Prompt for implementation planning.
The idea was to leverage each model’s strengths. Claude handles the file operations and manages the task structure, while ChatGPT analyzes the codebase and suggests implementation approaches. They literally chat with each other using the Repo Prompt MCP tool, with Claude asking questions and ChatGPT providing analysis. Sometimes I had to intervene to guide them back on track or stop them to wait for my approval on design decisions. It’s like having two developers pair programming, each bringing their own expertise to the planning session.
The approach surfaced some important design decisions. Instead of service objects, we’re going with Rails-idiomatic patterns: model methods, class methods on MonthlyAllocation, and callbacks for snapshots. Everything through ActiveRecord.
Planning Through Test Cases
The bulk of the work went into defining test specifications:
- 7 test cases for SomedayGoal
- 15 for MonthlyGoal (including top-up logic)
- 17 for DeadlineGoal (with auto-advance scenarios)
- 17 for ReserveGoal
Each test case addresses specific edge cases. What happens when a monthly goal already has surplus funds? How does a deadline goal behave when it’s past due? Getting these details right upfront matters.
All calculations will use “opening balance,” the balance at the start of the month, not the current balance. This prevents allocation amounts from changing as transactions flow through during the month, which matches how people think about budgets.
The session produced seven detailed task files ready for implementation. Each includes exact specifications, test cases, and implementation notes. The tasks cover Single Table Inheritance strategy, historical snapshots through callbacks, and model-driven allocation suggestions.
Tomorrow I’m letting Claude Code implement these tasks.
2025.07.10.
Pezeta Progress Log: Day 4
Had a focused session today expanding the goal system design for Pezeta. Yesterday I started with the basic concept, today I dove deeper into the details.
I expanded all four goal types with detailed logic and edge cases:
- Someday goals are your classic piggy bank. You want $3,000 for a new laptop someday. The system suggests funding it until you hit that target, then stops.
- Edge case: what happens if you change the target from $3,000 to $4,000? Only future months use the new target.
- Monthly goals keep a set amount available each month. You want $200 available for groceries each month. If you spend $150, you need $50 to top back up. If you somehow end up with $300, that’s fine – surplus is allowed.
- Edge case: what happens if you never spend anything? The surplus just sits there – no more funding needed.
- Deadline goals add time pressure. $2,000 for a vacation by next summer. The system calculates: you need $200 per month to hit that target.
- Edge case: what happens if you miss a month? The next month’s allocation jumps to catch up.
- Reserve goals are your safety nets. Keep at least $2,000 in emergency savings. If it dips to $1,500, fund $500 immediately.
- Edge case: what happens if you never touch it? No allocation needed – it’s already above the reserve.
So this session was used to think about these and take a deep dive in the goal rule engine inner workings. I still have questions but it will be iterated when I start using the MVP. I have goal examples in my current budget for all of these.
The technical challenge was handling goal changes over time. What happens if you change your vacation target from $2,000 to $3,000 in March? Should January’s allocation be recalculated as if you always wanted $3,000?
I went with a snapshot approach. Each month gets its own snapshot of goal parameters. Past months never change retroactively. January’s allocation was based on January’s goal settings, period. This preserves the audit trail of what you were thinking at the time.
2025.07.09.
Pezeta Progress Log: Day 3
Today wrapped up the core data foundation with the Budget view model and spent time planning the goal allocation rules that’ll make this budgeting app different.
The aggregation layer
The Budget model pulls everything together. Give it a ledger and a month, and it calculates the current state of all categories, their allocated amounts, actual spending, and remaining balances.
This is just pure Ruby class that takes the foundational models and presents them in a way that makes sense to users.
Goal allocation rules
The bigger breakthrough today was finalizing the goal allocation rules. This is what’ll set Pezeta apart from traditional envelope budgeting.
Instead of managing dozens of budget categories, users define their financial goals—things they actually care about saving for. The app figures out how much to allocate to each goal and shows one simple number: how much is safe to spend on everything else. Goals run in the background while you focus on that single “Safe to Spend” amount.
I want to implement four goal types:
- Someday: Save for something with no deadline—like a new laptop or vacation fund. Allocates the difference between target and current balance until you hit the goal.
- Monthly: Keep a certain amount available each month—like rent or groceries. Tops up to the monthly amount, and any surplus stays there.
- Deadline: Gather a lump sum by a specific date—like saving $3000 for a trip by July. Calculates how much to save each month based on time remaining.
- Reserve: Maintain a minimum balance at all times—like an emergency fund. Only allocates money when the balance dips below the reserve amount.
Each follows different allocation formulas, but the key insight is the engine just calculates expected allocations—it never moves money automatically. That stays under your control.
The vision coming together
I’ve got a React prototype artifact built with Claude that demonstrates how this will look. We have a simple “Safe to Spend” number on top, goals running quietly in the background. I just created this to validate the UX approach, but it shows the vision clearly.